Giới thiệu về microgpt
microgpt là một dự án nghệ thuật của tôi, một tệp Python với 200 dòng mã không phụ thuộc thư viện bên ngoài để huấn luyện và chạy một GPT. Đây là sự kết hợp từ nhiều dự án trước đó như micrograd, makemore, nanogpt để đơn giản hóa GPT với chỉ những gì cốt yếu.
Hình ảnh mô tả mã nguồn:
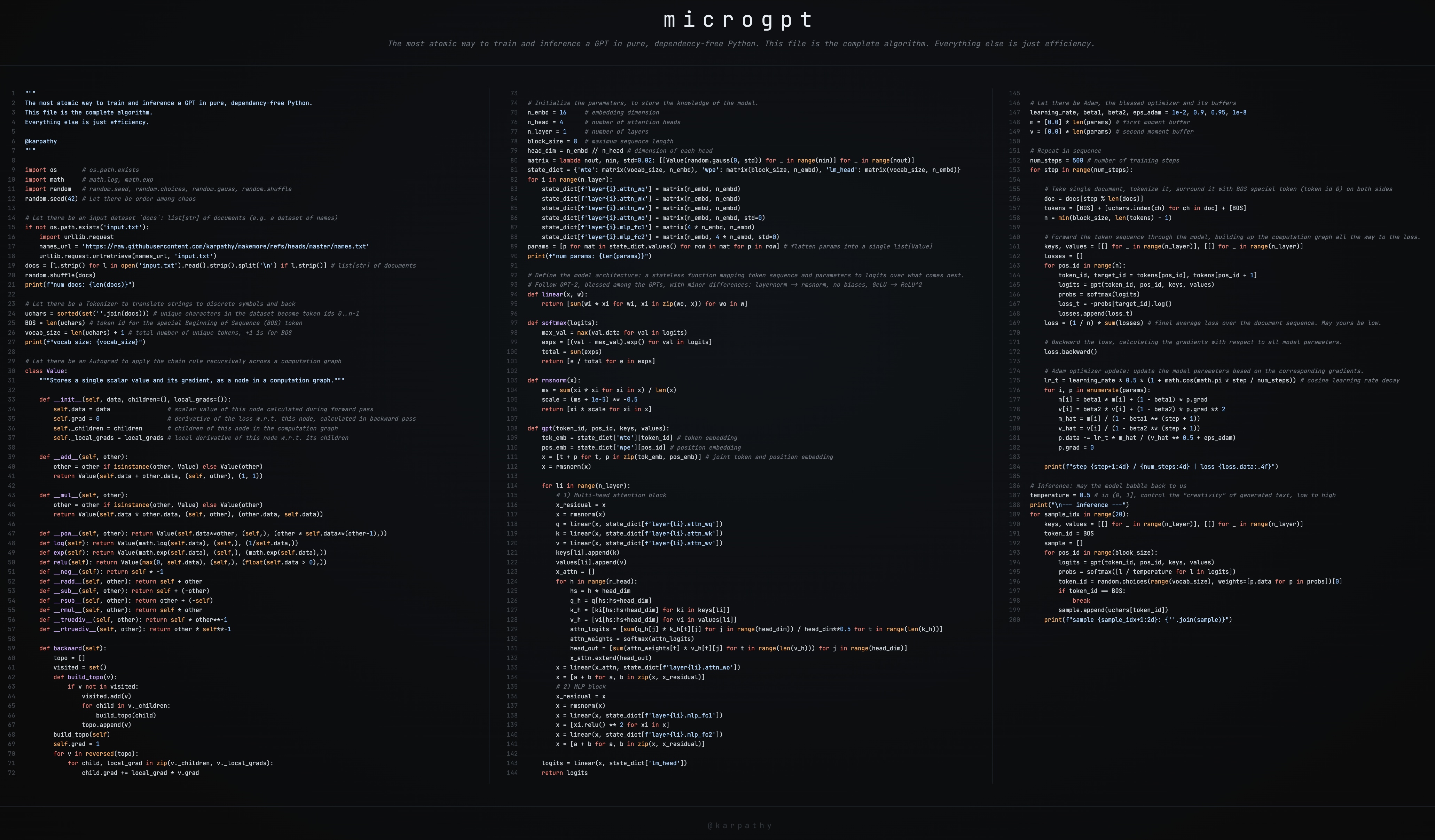
Nơi tìm thấy mã nguồn
- Mã nguồn đầy đủ trên GitHub: microgpt.py
- Trang web: https://karpathy.ai/microgpt.html
- Google Colab notebook: Trải nghiệm trên Colab
Hướng dẫn chi tiết
Dataset
Mã chuẩn bị dữ liệu
if not os.path.exists('input.txt'):
import urllib.request
names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt'
urllib.request.urlretrieve(names_url, 'input.txt')
docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()] # list[str] of documents
random.shuffle(docs)
print(f"num docs: {len(docs)}")Ví dụ dữ liệu
Dữ liệu bao gồm 32,000 tên:
emma
olivia
ava
isabella
sophia
...Tokenizer
Chuyển đổi ký tự thành số:
# Tokenizer
uchars = sorted(set(''.join(docs)))
BOS = len(uchars)
vocab_size = len(uchars) + 1
print(f"vocab size: {vocab_size}")Autograd
Lớp Value thực hiện hàm tính đạo hàm ngược:
class Value:
__slots__ = ('data', 'grad', '_children', '_local_grads')
def __init__(self, data, children=(), local_grads=()):
self.data = data
self.grad = 0
self._children = children
self._local_grads = local_grads
def __add__(self, other):
...
def __mul__(self, other):
...
def __pow__(self, other): return Value(self.data**other, (self,), (other * self.data**(other-1),))
...
def backward(self):
...Parameters
Khởi tạo tham số mô hình:
n_embd = 16
n_head = 4
n_layer = 1
block_size = 16
head_dim = n_embd // n_head
... # Khởi tạo các tham số khácArchitecture
Kiến trúc mô hình GPT đơn giản:
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id]
pos_emb = state_dict['wpe'][pos_id]
...
return logitsTraining loop
Vòng lặp huấn luyện mô hình:
# Initialization
learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8
m = [0.0] * len(params) ...
# Training
for step in range(num_steps):
...
print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")Inference
Mã tạo tên mới sau khi huấn luyện:
temperature = 0.5
for sample_idx in range(20):
...
print(f"sample {sample_idx+1:2d}: {''.join(sample)}")Thực thi
Chạy mã với Python không cần cài đặt thêm:
python train.pyBạn sẽ thấy loss giảm từ 3.3 xuống còn khoảng 2.37.
Tiến triển
Tiến trình phát triển mã:
| File | Nội dung |
|---|---|
train0.py | Bảng đếm bigram |
train1.py | MLP + đạo hàm thủ công |
train2.py | Autograd với lớp Value |
train3.py | Embedding vị trí và attention đơn giản |
train4.py | Attention đa đầu |
train5.py | Tối ưu hóa với Adam |
Xem chi tiết tại: build_microgpt.py
Những điểm nâng cao
microgpt giữ lại cốt lõi của GPT nhưng thiếu nhiều yếu tố thực tiễn cần thiết cho sản phẩm.
FAQ
Mô hình có thực sự “hiểu” không? Không có gì huyền bí, mô hình chỉ là hàm toán học dự đoán token tiếp theo.
Tại sao nó hoạt động? Thông qua hàng ngàn bước, các tham số tự điều chỉnh theo các quy tắc thống kê.
Hiểu microgpt giúp bạn nắm được thuật toán cốt lõi của các mô hình dạng GPT lớn.