Compute vs Dữ liệu
Tăng trưởng của tính toán nhanh hơn nhiều so với dữ liệu. Các quy luật hiện tại yêu cầu mức độ tỷ lệ tương đương ở cả hai để mở rộng, nhưng sự bất đối xứng trong tăng trưởng này có nghĩa rằng trí tuệ cuối cùng sẽ bị giới hạn bởi dữ liệu, không phải bởi tính toán. Điều này dễ nhận thấy trong các lĩnh vực như robot và sinh học, nơi yêu cầu dữ liệu lớn dẫn đến các mô hình yếu, và cả hai lĩnh vực đều có động lực kinh tế để tận dụng 1000x tính toán nếu điều đó mang lại kết quả tốt hơn đáng kể. Tuy nhiên, người ta không thể thực hiện điều đó mà không thêm dữ liệu. Giải pháp là tạo ra các thuật toán học mới hoạt động tốt trong điều kiện dữ liệu hạn chế và tính toán gần như vô hạn. Đây là điều chúng tôi đang giải quyết tại Q Labs: mục tiêu của chúng tôi là hiểu và giải quyết vấn đề tổng quát hóa.
NanoGPT Slowrun baseline: 2.4x Hiệu quả Dữ liệu
Tuần trước, chúng tôi đã phát hành NanoGPT Slowrun, một kho mở cho các thuật toán học hiệu quả dữ liệu. Quy tắc đơn giản: đào tạo trên 100 triệu tokens từ FineWeb, sử dụng càng nhiều tính toán càng tốt, người nào có độ mất xác minh thấp nhất sẽ thắng. Các cải tiến được nộp qua PR lên kho và sẽ được gộp nếu giảm được độ mất xác minh. Giới hạn này hoàn toàn ngược lại với các cuộc chạy tốc độ như modded-nanogpt, tối ưu hóa thời gian đồng hồ treo tường. Các tiêu chuẩn đó đã rất sản xuất, nhưng tối ưu cho tốc độ thì loại bỏ những ý tưởng đắt đỏ như điều tiết mạnh, bộ tối ưu hóa thứ hai, các thay thế cho gradient descent. Slowrun được xây dựng chính xác cho những ý tưởng này.
Những phát hiện từ trước đến nay
- Muon vượt trội hơn mọi bộ tối ưu hóa đã thử nghiệm (AdamW, SOAP, MAGMA).
- Đào tạo đa kỳ quan trọng.
- Theo Kotha và cộng sự, mở rộng đến số lượng tham số lớn hiệu quả nếu kết hợp với điều chỉnh mạnh — giảm trọng lượng lên đến 16x tiêu chuẩn, cộng với dropout.
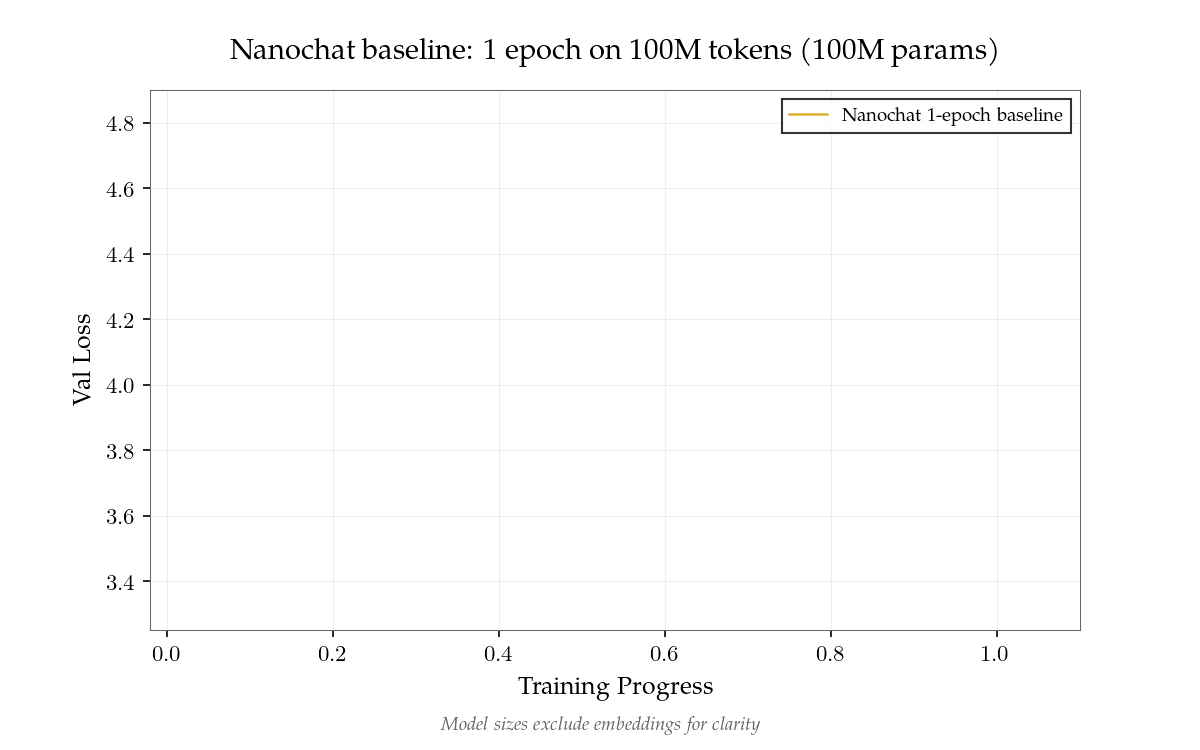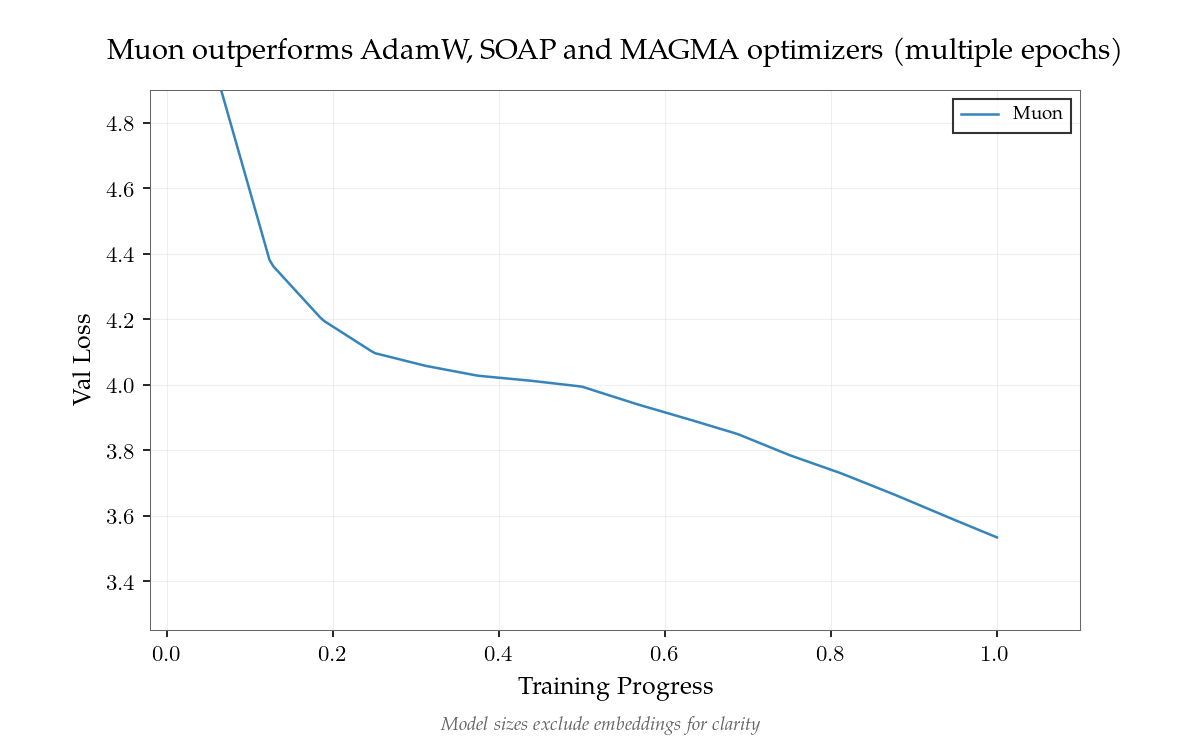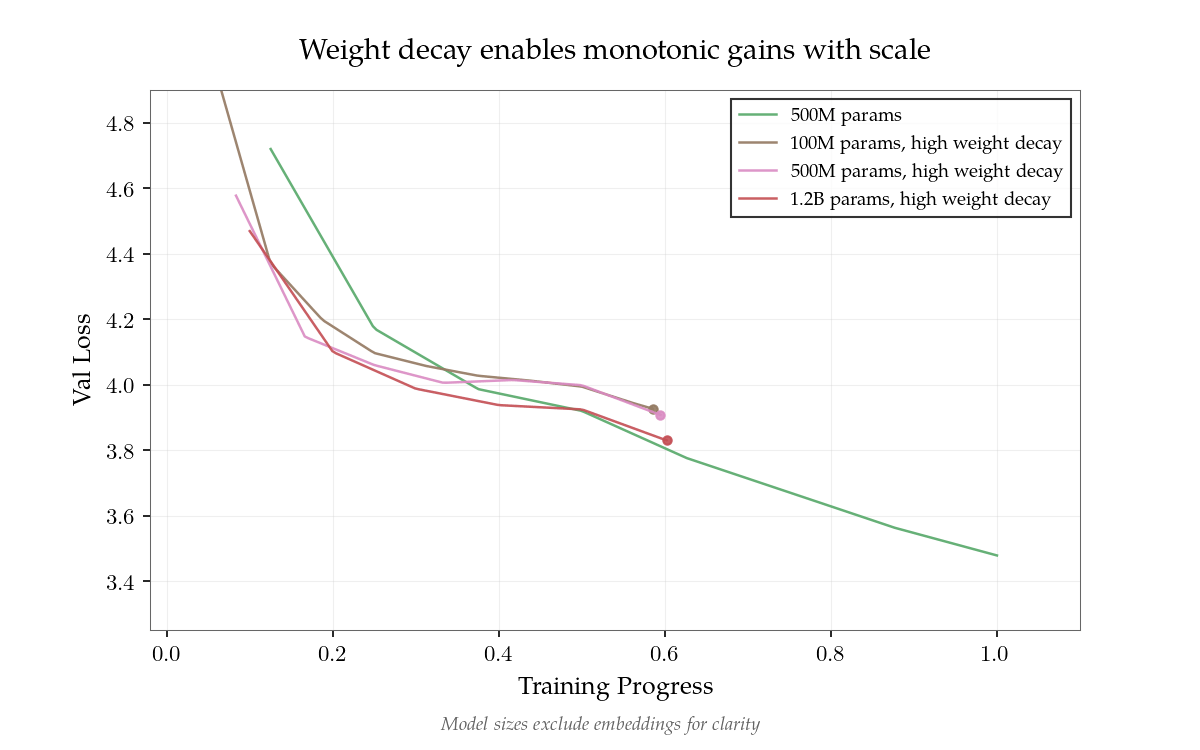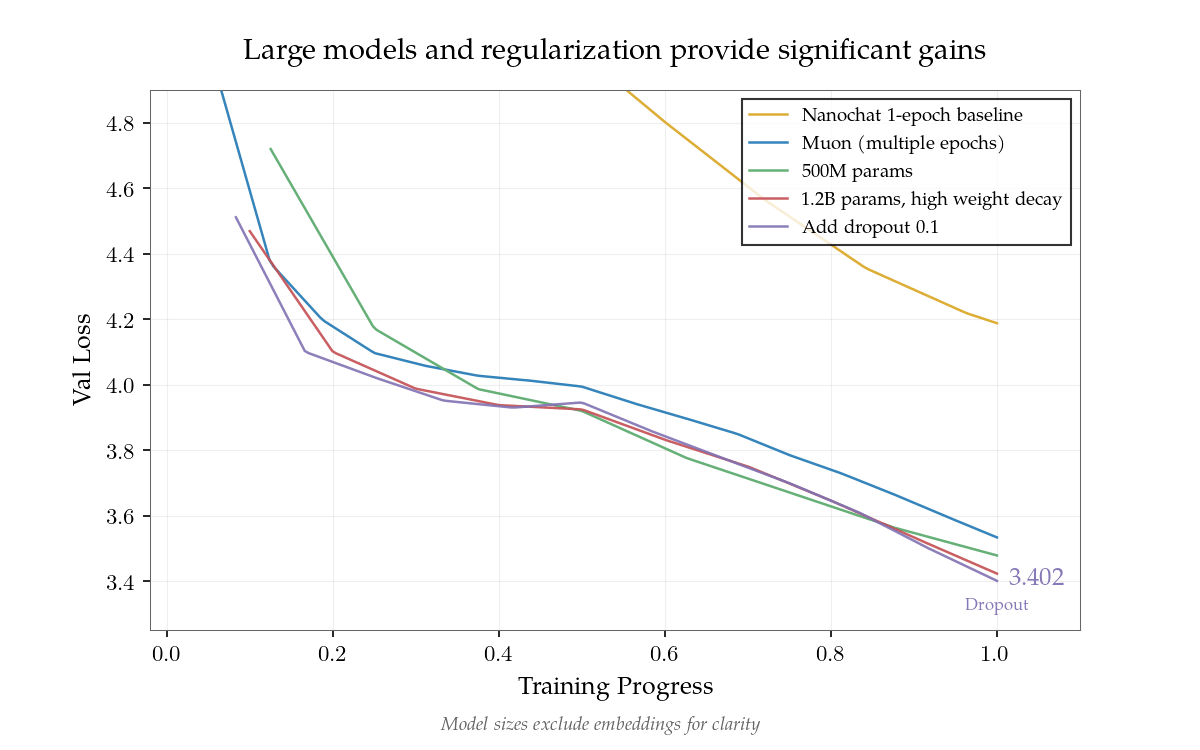
- Cơ sở hiện tại có hiệu quả dữ liệu khoảng 2.4x so với modded-nanogpt.
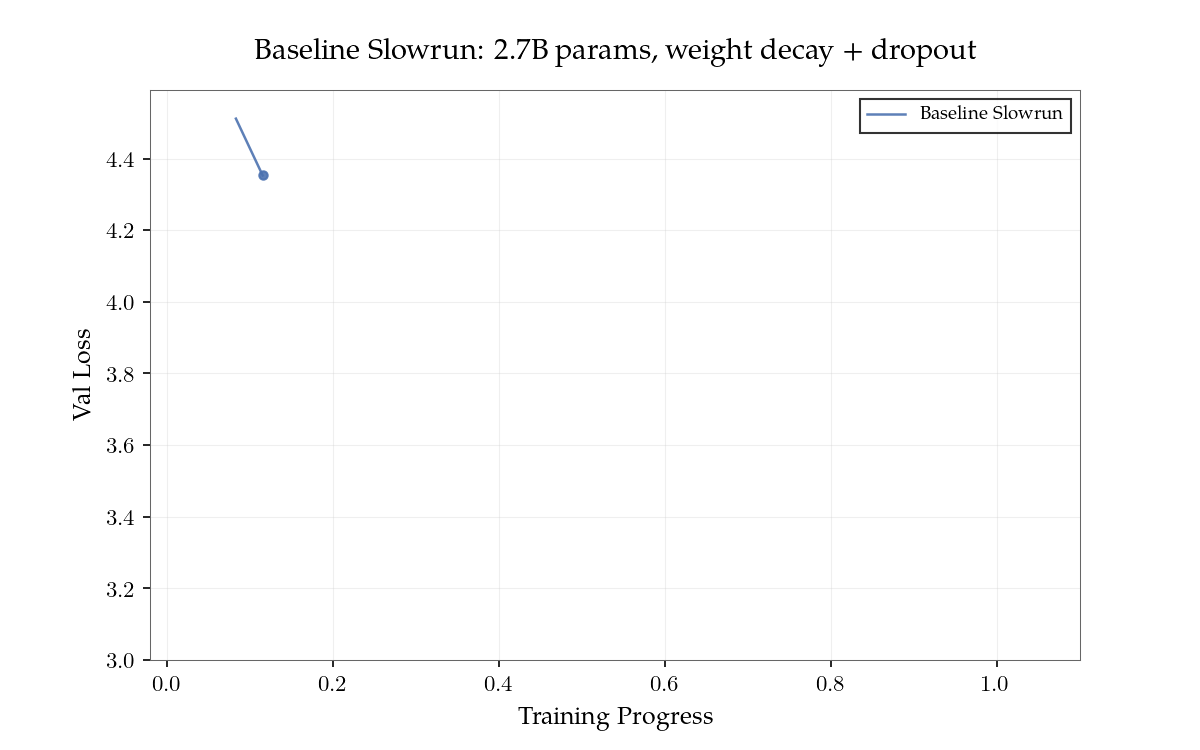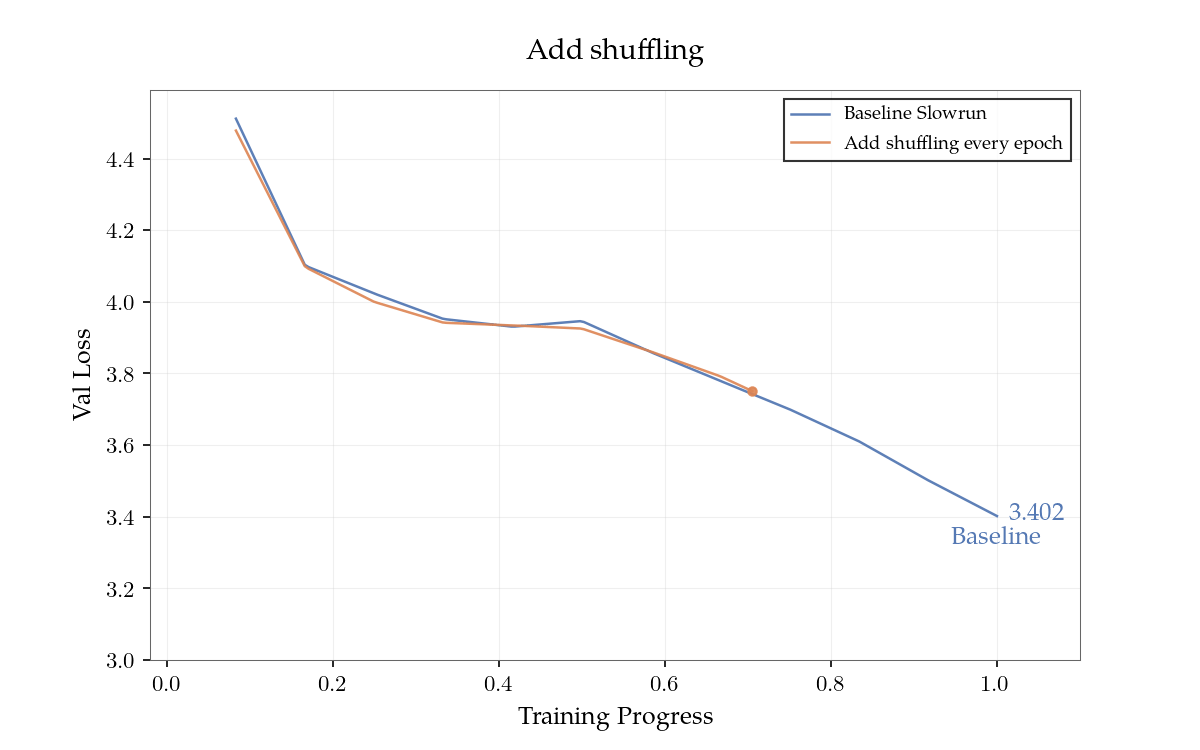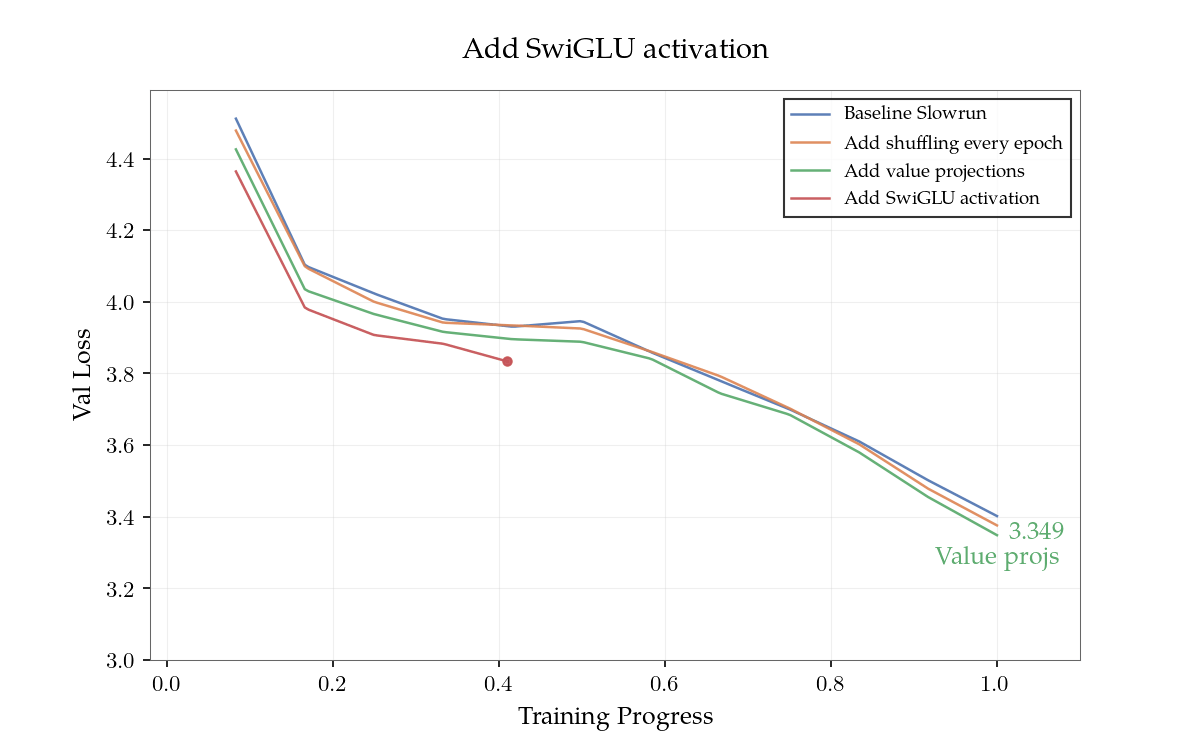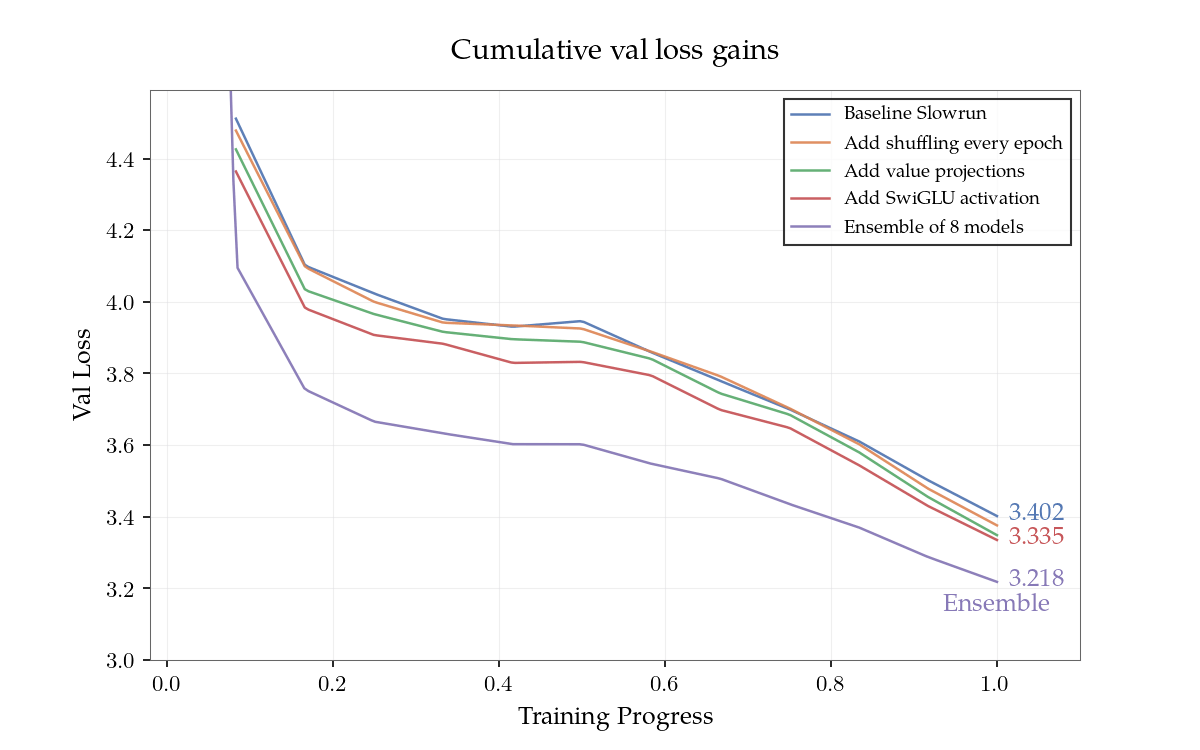
Cập nhật: 5.5x Hiệu quả Dữ liệu
Kể từ khi phát hành ban đầu, đóng góp từ cộng đồng đã nâng cao hiệu quả dữ liệu từ khoảng 2.4x lên 5.5x so với modded-nanogpt, tăng hơn gấp đôi trong vài ngày. Những thay đổi quan trọng là: trộn lẫn dữ liệu vào đầu mỗi kỳ đào tạo, tạo tác động lớn đến đào tạo đa kỳ; sử dụng các dự kiến học được cho giá trị nhúng hơn là các bảng nhúng riêng biệt; thay thế ReLU bình phương bằng kích hoạt SwiGLU; và tập hợp nhiều mô hình. Hiệu quả dữ liệu 10x có vẻ đạt được trong thời gian ngắn. 100x có thể đạt được vào cuối năm, nếu có sự khám phá sâu rộng về mặt thuật toán.
Các hướng đi có tiềm năng lớn
- Bộ tối ưu hóa bậc hai và phương pháp gradient tự nhiên
- Mô hình khuếch tán
- Học tập có giáo trình
- Các thay thế cho gradient descent như tìm kiếm tiến hóa
- Tối ưu hóa cho nén hay độ phức tạp của mô hình
Nếu bạn đang làm việc về bất kỳ điều nào trên hoặc điều chúng tôi chưa nghĩ tới, hãy mở một vấn đề trên repo, hoặc gửi email tới research@qlabs.sh.